You Only Recognize Once: Towards Fast Video Text Spotting
Abstract
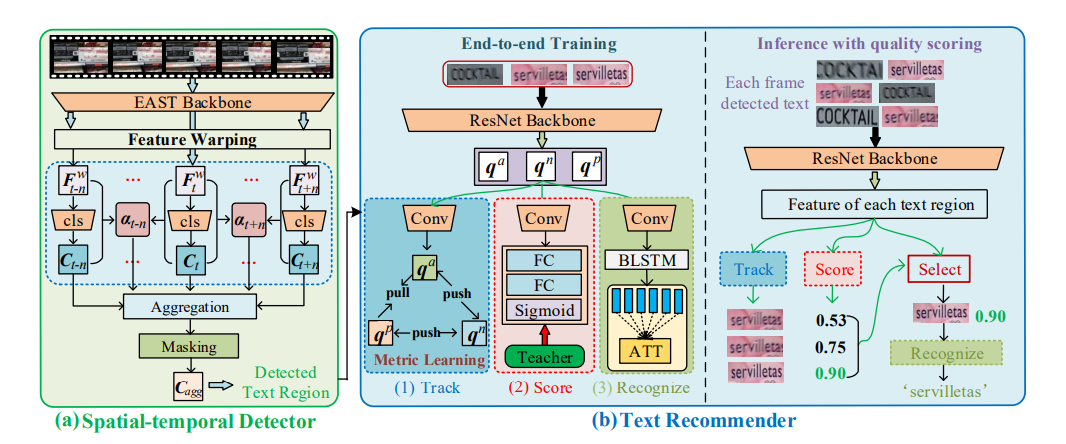
Video text spotting is still an important research topic due to its various real-applications. Previous approaches usually fall into the four-staged pipeline: text detection in individual images, framewisely recognizing localized text regions, tracking text streams and generating final results with complicated post-processing skills, which might suffer from the huge computational cost as well as the interferences of low-quality text. In this paper, we propose a fast and robust video text spotting framework by only recognizing the localized text one-time instead of frame-wisely recognition. Specifically, we first obtain text regions in videos with a well-designed spatial-temporal detector. Then we concentrate on developing a novel text recommender for selecting the highest-quality text from text streams and only recognizing the selected ones. Here, the recommender assembles text tracking, quality scoring and recognition into an end-to-end trainable module, which not only avoids the interferences from low-quality text but also dramatically speeds up the video text spotting process. In addition, we collect a larger scale video text dataset (LSVTD) for promoting the video text spotting community, which contains 100 text videos from 22 different real life scenarios. Extensive experiments on two public benchmarks show that our method greatly speeds up the recognition process averagely by 71 times compared with the frame-wise manner, and also achieves the remarkable state-of-the-art. [Paper] [Dataset]Highlights Contributions
❃ We design a novel text recommender for selecting the highest-quality text from text streams and then only recognizing the selected text regions once, which significantly speeds up the recognition process, and also improves the video text spotting performance.
❃ We integrate a well-designed spatial-temporal text detector and a text recommender into an unified two-stage framework YORO for fast end-to-end video text spotting.
❃ In order to promote the progress of video text spotting, we collect and annotate a larger scale video text dataset, which contains 100 videos from 22 different real-life situations.
❃ Extensive experiments demonstrate that our method is fast and robust and achieves impressive performance in video scene text reading.
Recommended Citations
If you find our work is helpful to your research, please feel free to cite us:
@inproceedings{cheng2019you,
title={You Only Recognize Once: Towards Fast Video Text Spotting},
author={Cheng, Zhanzhan and Lu, Jing and Niu, Yi and Pu, Shiliang and Wu, Fei and Zhou, Shuigeng},
booktitle={Proceedings of the 27th ACM International Conference on Multimedia},
pages={855--863},
year={2019},
organization={ACM}
}