Document layout recognition (ICDAR 2021 Competition on Scientific Literature Parsing, Task A)
DAVAR LAB
Official Website
Introduction
This competition aims to advance the research in recognizing the layout of unstructured documents. Participants of this competition need to develop a model that can identify the common layout elements in document images, including text, titles, tables, figures, and lists, with confidence score for each detection.
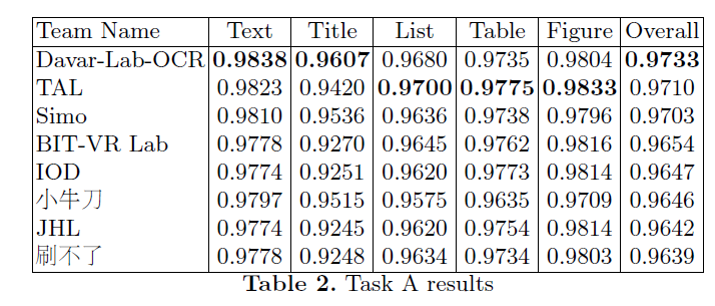
We have won the 1st place out of 80 teams in this timed challenge!

System Description
The system is built based on a multi-modal Mask-RCNN-based object detection framework. For a document, we make full use of the advantages from vision and semantics, where the vision is introduced in the form of document image, while semantics (texts and positions) is directly parsed from PDF. We adopt a two-stream network to extract modality-specific visual and semantic features. The visual branch processes document image and semantic branch extracts features from text embedding maps (text regions are filled with the corresponding embedding vectors, which are learned from scratch). The features are fused adaptively as the complete representation of document, and then are fed into a standard object detection procedure.
To further improve accuracy, model ensemble technique is applied. Specifically, we train two large multimodal layout analysis models (a. ResNeXt-101-Cascade DCN Mask RCNN; b. ResNeSt-101-Cascade Mask RCNN), and inference the models in several different scales. The final results are generated by a weighted bounding-boxes fusion strategy.
For more details, please refer to our research paper: VSR: A Unified Framework for Document Layout Analysis combining Vision, Semantics and Relations