Table recognition (ICDAR 2021 Competition on Scientific Literature Parsing, Task B)
DAVAR LAB
Official Website
Introduction
Participants of this competition need to develop a model that can convert images of tabular data into the corresponding HTML code. The targeted HTML code should correctly represent the structure of the table and the content of each cell. HTML tags that define the font style including bold, italic, strike through, superscript, and subscript should be included in cell content. The HTML code does NOT need to reconstruct the appearance of tables such as border lines, background color, font, font size, or font color. The figure below illustrates an example table image and its targeted HTML code. Note that the targeted HTML code does not contain the settings about border lines, background color of the header row, or the blue font color of 'Woof'.
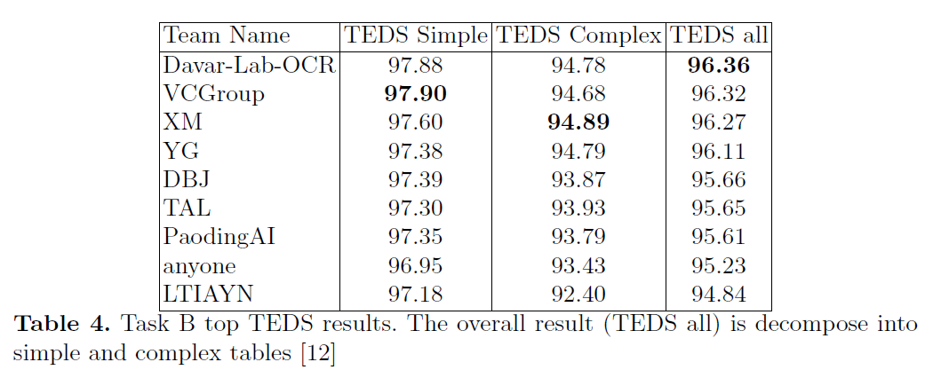
We have won the 1st place out of 30 teams in this timed challenge!

System Description
The table recognition framework contains two main processes: table cells generation and structure inference.
(1) Table cells generation is built based on the Mask-RCNN detection model. Specifically, the model is trained to learn the row/column aligned cell-level bounding boxes with corresponding mask of text content region. We introduce the pyramid mask supervision and adopt a large backbone of HRNet-W48 Cas- cade Mask RCNN to obtain the reliable aligned bounding boxes. In addition, we train a single-line text detection model with an attention-based text recognition model to provide the OCR information. This is simply achieved by selecting the instances that only contain single-line text. We also adopt multi-scale ensemble strategy on both the cell and single-line text detection models to further improve performance.
(2) In the structure inference stage, the bounding boxes for cells can be horizontally/vertically connected according to their alignment overlaps. The row/column information is then generated via a Maximum Clique Search pro- cess, during which empty cells can be easily located.
To handle some special cases, we train another table detection model to filter out text not belonging to the table.
For more details, please refer to our research paper: LGPMA: Complicated Table Structure Recognition with Local and Global Pyramid Mask Alignment